分布式缓存
缓存模式
Cache-Aside (Lazy Loading)
在该模式下,缓存中没有被请求的数据,应用程序首先只是查询缓存是否已经有了对应的数据,如果有数据,则直接返回给客户端;否则,应用程序从数据库读取数据,并将其放入到缓存中,再返回给用户的同时,也把数据保存在缓存中。此时,相当于缓存通过“旁路”方式来加载数据。
Read/Write Through
与 Cache-Aside 相比,Read/Write Through 将数据的读取和写入责任转给了缓存,不再由应用程序控制读写数据库,应用程序只需读取和写入缓存,缓存在读取和写入数据库。
Write-Behind (Write-Back)
Write-Behind 是指在进行数据持久化存储的时候,缓存系统不会立即将数据写入到磁盘或者数据库中,而是会先将数据写入到一个本地的缓存区中,并标记为“脏”数据。可以理解写是异步的。
Refresh-Ahead
Refresh-Ahead 是一种数据缓存机制,在需要访问某个数据块之前,系统会预先将相邻的若干数据块加载到缓存中以提高访问效率。这种机制可以减少因为频繁从数据库读数据而导致的性能瓶颈。
缓存问题
数据污染
版本一:保证时效和一致性
Storage 和 Cache 同步更新容易出现数据不一致。 模拟 MySQLSlave 做数据复制,再把消息投递到 Kafka,保证至少依次消费:
- 同步操作 DB;
- 同步操作 Cache;
- 利用 Job 消费消息,重新补偿依次缓存操作。
版本二:HappensBefore 问题
CacheAside 模型中,读缓存Miss的回填操作,和修改数据同步更新缓存,包括消息队列的异步补偿缓存,都无法满足"HappensBefore",会存在相互覆盖的情况。
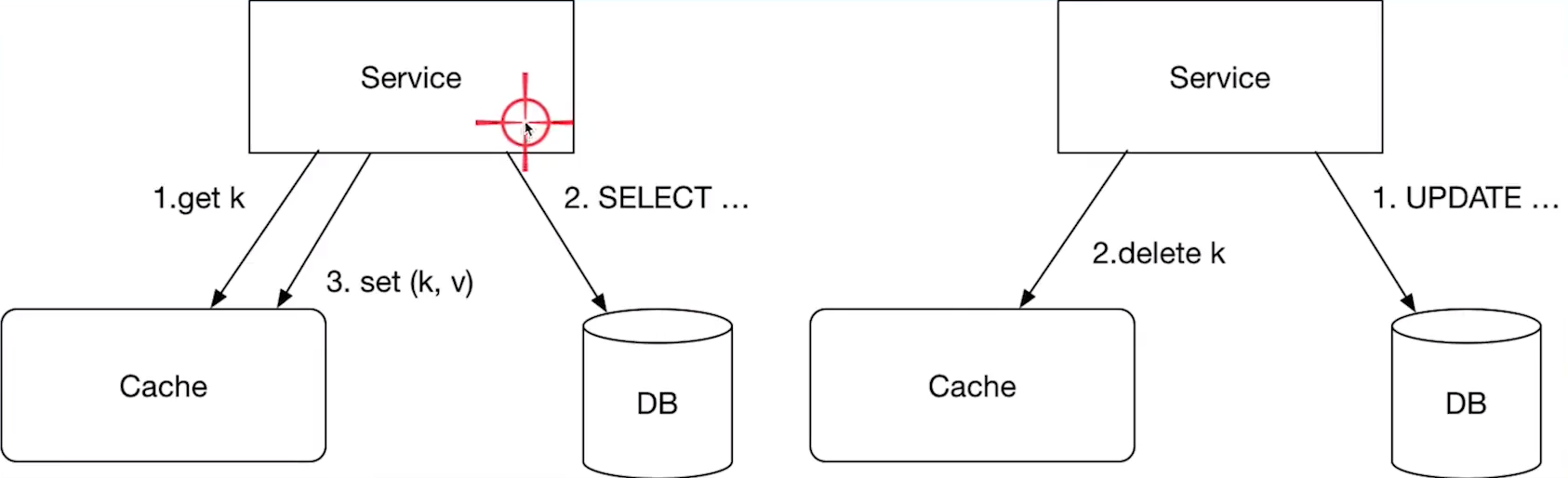
产生数据不一致的步骤
线程A执行 1,2 步骤线程B执行 1,2 步骤线程A执行第 3 步骤set(k,v),将旧数据写入了缓存(脏读)
版本三:读写同时操作
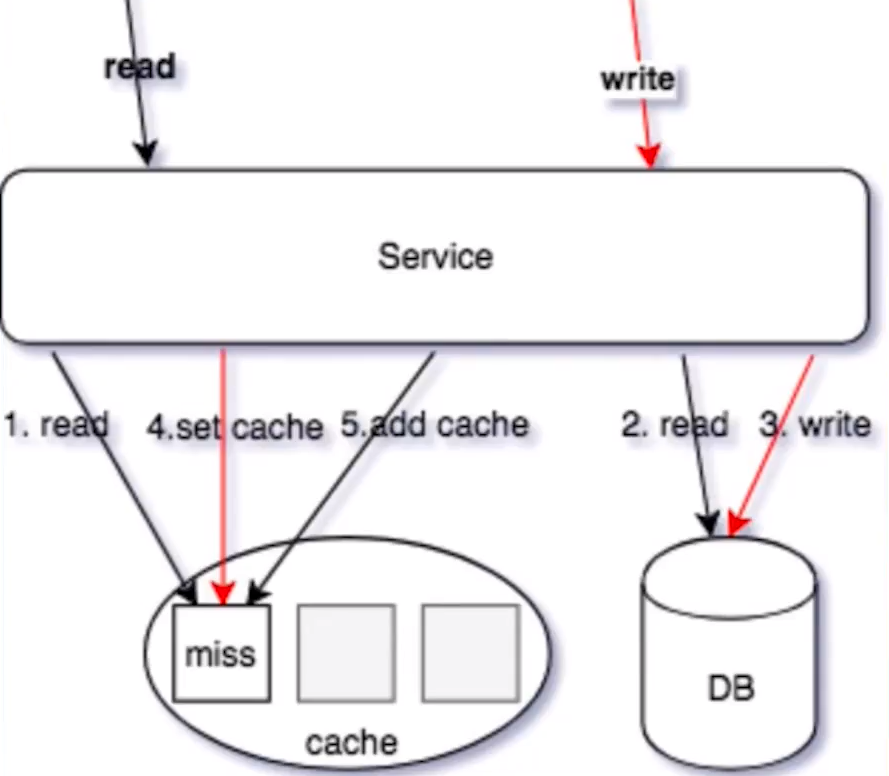
读/写同时操作:
线程A读操作,读缓存,缓存 MISS线程A读操作,读 DB,读取到数据线程B写操作,更新 DB 数据线程B写操作 SET/DELETECache(可 Job 异步操作)写操作 SETCache(可异步 job 操作,Redis 可以使用SETEX操作)线程A读操作,SET 操作数据回写缓存(可 Job 异步操作)读操作,ADD 操作数据回写缓存(可 Job 异步操作,Redis 可以使用SETNX操作)
删除线的这种交互下,由于 4 和 5 操作步骤都是设置缓存,导致写入的值相互覆盖;并且操作的顺序性不确定,从而导致 cache 存储在脏缓存的情况。
正确的操作步骤
-
写操作使用 SET 操作命令,覆盖写缓存;
-
读操作,使用 ADD 操作回写 MISS 数据,从而保证写操作的最新数据不会被读操作的回写数据覆盖。
问题
如果 Update 了 5 次,消息消费会 5 次,用户可能会看到不一致(临时不一致),如果解决?
缓存穿透
对于一个查询的数据,由于在数据源不存在这个数据,从而导致这个查询请求穿过缓存层直接到达了数据源,从而可能瞬间将后端数据存储层压垮。缓存穿透多出现在恶意攻击和大量请求条件不符的情况。攻击者通过构造不存在的请求查询条件来使得所有的请求都落到后端数据库上,后端由于无法从缓存中查询到结果而不断地创建新连接,最终导致系统宕机。
- 业务逻辑无法避免的缓存穿透问题,可以约定在一定时间内对返回为空的 Key 值进行缓存,保证在一段时间内最多只被穿透一次。
- 对于恶意攻击导致的缓存穿透,通常会在缓存之前设置一个布隆过滤器来解决。
缓存击穿
缓存中没有但数据库中有的数据,一般因为这些数据很少被查询,所以并没有被缓存起来,当查询这些数据时,缓存会失效,此时如果大量请求同时落到缓存中,就容易瞬间压垮后端数据库。另外,缓存设置过期时间,如果在其过期时间段内,某个热点 key 失效,此时也会导致大量请求同时落到后端数据库。
- 加锁同步:以请求该数据的 Key 值为锁,使得只有第一个请求可以流入真实的数据源中,对其他线程则采取阻塞或重试策略。防止数据源出现大量针对同一个数据的请求了。
- 热点数据:通过业务代码保证有计划地完成更新、失效,避免由缓存的策略自动管理。
- 小表广播,从 RemoteCache 提升为 LocalCache,App 定时更新,甚至可以让运营平台支持广播刷新 LocalCache;
- 主动监控防御预热,比如直播房间页高在线情况下直接外挂服务主动防御;
- 基础库框架支持热点发现,自动短时的 shortlivecache;
- 多 Cluster 支持;
- 多 Key 设计:使用多副本,减小节点热点的问题
- 使用多副本 ms_1,ms_2,ms_3 每个节点保存一份数据,使得请求分散到多个节点,避免单点热点问题。
- 多 Key 设计:使用多副本,减小节点热点的问题
缓存雪崩
在某个时间段内,缓存集中过期失效,而导致原本应该访问缓存的请求全部转发到后端,负载骤增,甚至引发系统崩溃的一种现象。
- 分布式缓存的集群。
- 多级缓存,最重要的是保证多级缓存的一致性。
- 清理的优先级是有要求的,先优先清理下游再上游;
- 如果先清理上游再清理下游,会有脏读。
- 下游的缓存 expire 要大于上游,里面穿透回源。
- 清理的优先级是有要求的,先优先清理下游再上游;
- 缓存固定过期改成随机时间。
缓存技巧
IncastCongestion
如果在网路中的包太多,就会发生 IncastCongestion 的问题(可以理解为,network 有很多 switch,router 啥的,一旦一次性发一堆包,这些包同时到达 switch,这些 switch 就会忙不过来)。
应对这个问题就是不要让大量包在同一时间发送出去,在客户端限制每次发出去的包的数量(具体实现就是客户端弄个队列)。
每次发送的包的数量称为"Windowsize"。这个值太小的话,发送太慢,自然延迟会变高;这个值太大,发送的包太多把 networkswitch 搞崩溃了,就可能发生比如丢包之类的情况,可能被当作 cachemiss,这样延迟也会变高。所以这个值需要调,一般会在 proxy 层面实现。
小技巧
- 易读性的前提下,key 设置尽可能小,减少资源的占用,redisvalue 可以用 int 就不要用 string,对于小于 N 的 value,redis 内部有 shared_object 缓存。
- 拆分 key。主要是用在 redis 使用 hashes 情况下。同一个 hasheskey 会落到同一个 redis 节点,hashes 过大的情况下会导致内存及请求分布的不均匀。考虑对 hash 进行拆分为小的 hash,使得节点内存均匀及避免单节点请求热点。
- 空缓存保护策略。对于部分数据,可能数据库始终为空,这时应该设置空缓存,避免每次请求都缓存 miss 直接打到 DB。
- 读失败后的写缓存策略(降级后一般读失败不触发回写缓存)。
- 序列化使用 protobuf,尽可能减少 size。
- 工具化浇水代码
Redis
- 增量更新一致性:EXPIRE 后 ZADD/HSET 等,保证索引结构体务必存在的情况下去操作新增数据;
- BITSET:存储每日登陆用户,单个标记位置(boolean),为了避免单个 BITSET 过大或者热点,需要使用 region sharding,比如按照 mid 求余%和/10000,商为 KEY、余数作为 offset;
- List:抽奖的奖池、顶弹幕,用于类似 Stack PUSN/POP 操作;
- Sortedset:翻页、排序、有序的集合,杜绝 Lrange 或者 zrevrange 返回的集合过大;
- Hashs:过小的时候会使用压缩列表、过大的情况容易导致 rehash 内存浪费,也杜绝返回 hgetall,对于小结构体,建议直接使用 memcache KV;
- String:SET 的 EXNX 等 KV 扩展指令,SETNX 可以用于分布式锁、SETEX 聚合了 SETEXPIRE;Sets:类似 Hashs,无 Value,去重等;
- 尽可能的 PIPELINE 指令,但是避免集合过大;
- 避免超大 Value;